Pragma Integrity Chec
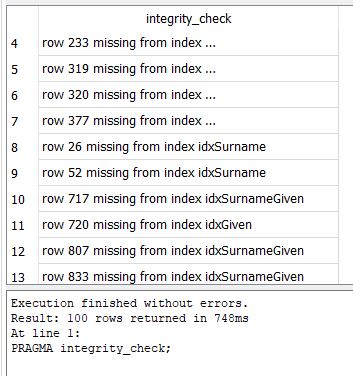
Quote from kevync on 2022-03-31, 8:28 pmRM Tools do not report anything. DB Browser SQLite reports the following. I exported and imported GEDCOM and got same results. Can any provide insight?
RM Tools do not report anything. DB Browser SQLite reports the following. I exported and imported GEDCOM and got same results. Can any provide insight?
Uploaded files:
Quote from Tom Holden on 2022-04-01, 12:40 pmI responded in the RM Community here, copied below:
Does DBbrowser support adding a RMNOCASE extension? If not, that may be at the root of your problem. Using SQLiteSpy with the fake RMNOCASE extension, the PRAGMA Integrity_Check has errors when the RM7 or RM8 database which passes RM’s Check Integrity is first opened. After running SQLite REINDEX, no errors in SQLite. However, on returning to RM, it does and it is necessary to Rebuild Indexes to clear the errors. These errors stem from the mismatch between RM’s proprietary collation sequence and the fake one. The fake using unifuzz.dll is a closer match than the one which gives the built-in NOCASE the alternate name RMNOCASE, thus resulting in fewer errors in both directions. It’s advisable to reindex in the application in use to avoid possible errors in search and other matching or sorting processes but I’ve been pretty lazy about it and cannot recall a problem - could be a bigger problem for characters outside the ANSII character set.
There can be errors outside of indexing that cannot be cleared by either. That’s indicative of some type of database corruption.
I responded in the RM Community here, copied below:
Does DBbrowser support adding a RMNOCASE extension? If not, that may be at the root of your problem. Using SQLiteSpy with the fake RMNOCASE extension, the PRAGMA Integrity_Check has errors when the RM7 or RM8 database which passes RM’s Check Integrity is first opened. After running SQLite REINDEX, no errors in SQLite. However, on returning to RM, it does and it is necessary to Rebuild Indexes to clear the errors. These errors stem from the mismatch between RM’s proprietary collation sequence and the fake one. The fake using unifuzz.dll is a closer match than the one which gives the built-in NOCASE the alternate name RMNOCASE, thus resulting in fewer errors in both directions. It’s advisable to reindex in the application in use to avoid possible errors in search and other matching or sorting processes but I’ve been pretty lazy about it and cannot recall a problem - could be a bigger problem for characters outside the ANSII character set.
There can be errors outside of indexing that cannot be cleared by either. That’s indicative of some type of database corruption.