Two SQLite queries developed by DeepSeek under my direction:
Update the Reverse column in PlaceTable from the Name, a comma-separated string
Count the number of commas in Place Name for each Place
These queries can be adapted to other SQLite database columns that employ comma-separated strings.
Problem
These queries were created when I was asked to convert Place Details into Places in a very large database with 48,000 records in the PlaceTable. I was able to use my old scripts from Places – Conversion of Place Details to Places to do the conversion but RM9 and RM10 have an added column in PlaceTable since those scripts were developed. The Reverse column is another un-normalised element that RM Inc has employed supposedly to expedite display of Place Names in reverse order in response to the “Reverse places” control on the Places pane on the More Options list under the 3-dot vertical ellipsis. That field is updated when a place is added or edited by the RM application but is untouched by my old script which resulted in an empty or null Reverse for the new Places it created. That made the reversed places display virtually useless. I needed a way to update Reverse from the place Name.
Analysis
The Place Names resulting from the conversion are stored in the PlaceTable in a comma-separated string of elements typically containing placedetail (itself could have commas), municipality, county, state/prov, country. However, users are unconstrained by the software and any number and nature of elements might be present, including phrases and complete sentences. There could be any number of commas in a Name string, it could be an empty string or a null or have consecutive commas. What we need in the Reverse column is the same elements in reverse order, e.g., country, state/prov, county, municipality, placedetail (itself could have commas).
Solution
From the RM6 or RM7 era, I had developed PlaceReverse.sql to display Places with up to 3 commas in reverse order. Looking at it now, it seems like a clumsy method and would not scale well. So I returned to AI, giving DeepSeek another shot at developing a query. While it seemed ponderously slow compared to Gemini Flash 2.5 as it typed out its ‘thinking’ at human typing speed, the first iteration worked! With a couple more tweaks, we improved its performance to process the 48,000 records from a few minutes to a few seconds and then constrained it to operate only on user-defined Places, ignoring the built-in LDS Temples and any Place Detail records, to achieve the desired results in 2-3 seconds (your mileage will vary).
While working on this big database, I was encountering occasional anomalies in the resulting combinations of PlaceDetail and Place into Place (I’ve since concluded, more or less, that it was my human factor that messed a few things up). But with 48,000 Places, a quarter-million people, RM10 was proving exceedingly slow at scrolling the Place List (and just about everything else). I thought a query that counted commas in the Place Name might catch anomalies of the kind I had seen, e.g., two different Place Names concatenated into one. So I asked DeepSeek to help and, kicking myself that I didn’t think of this method, it produced:
( Should be compatible with all versions from RM4 to #RM11 )
--count commas in Place Name SELECT PlaceID, CASE WHEN Name IS NULL THEN NULL ELSE LENGTH(Name) - LENGTH(REPLACE(Name, ',', '')) END AS comma_count, Name FROM PlaceTable ORDER BY comma_count DESC ;
Breakthrough! Something I’ve wanted for as long as I can remember is a means of detecting lineage loops (an ancestor is their own descendant) in family tree databases created with RootsMagic. This is my second major interaction with Google Gemini Flash 2.5 which took 18 attempts (only 18!) with lots of testing to nail down what I think is amazingly smart code that I could never have conceived and don’t fully understand. It’s robust and highly efficient. Added 2025-08-22: Explanation of script.Updated 2026-07-23: compatible with #RM11 .
Requires a RM group named “SQLite Lineage Loop Detector” to contain the people (from 1 to everyone) for whom an ancestral loop is to be sought. Faster than the original when the group is small; better for tackling a very large database. Also returns a “No loop detected” message. Compatible with RM8-RM11 databases. 2025-07-27
Screenshot above and redacted result copied from SQLiteSpy of two loops from a large database.
Child in Problematic Family Link
Full Loop Path (IDs)
Problematic Father (Descendant of Child)
Problematic Mother (Descendant of Child)
Family Where Loop Occurs
John Zzzzz-42789
42789->42789
N/A
N/A
John Zzzzz-42789=N/A
Duane Michael Xxxxxx-44066
44066->44078->44066
Anthony Michael Xxxxxx-44078
N/A
Anthony Michael Xxxxxx-44078=Verna Mildred Yyyyy-44058
Gemini generated the following description, covering what the script does, its design principles, and expected performance:
RM-LineageLoopDetector.sql: Uncovering Lineage Loops in RootsMagic Databases
Genealogical databases, especially those built over many years or compiled from various sources, can sometimes contain logical inconsistencies known as “lineage loops” or “pedigree loops.” These occur when an individual is recorded as being their own ancestor, or an ancestor of their parent, creating an impossible cycle in the family tree. While RootsMagic is designed to prevent some direct entry errors, more complex or indirect loops can slip through.
The RM-LineageLoopDetector.sql script is a powerful SQLite query specifically designed to identify and report these problematic lineage loops within your RootsMagic database.
What it Does
This script scans your RootsMagic database to find instances where:
A person is recorded as their own parent/ancestor (self-loop).
A person’s parent is also a descendant of that person (a more complex cycle).
For each loop detected, the script provides clear, actionable information:
Child in Problematic Family Link: The individual whose family relationship initiates the discovered loop.
Problematic Father / Mother (Descendant of Child): Identifies which parent in the problematic family is also a descendant of the child.
Family Where Loop Occurs: Provides a user-friendly representation of the family (e.g., “Father’s Name-ID=Mother’s Name-ID”) that contains the specific link causing the loop. This is crucial for RootsMagic users, as FamilyIDs are not visible in the application’s interface.
Full Loop Path (IDs): A sequence of PersonIDs illustrating the exact path taken to complete the loop, making it easy to trace the issue within RootsMagic.
The script is carefully designed to report only one canonical instance for each unique lineage loop, avoiding redundant results even if multiple paths within the loop could technically trigger detection.
How it Was Designed
The development of this script involved an iterative process to balance accuracy, performance, and user-friendliness:
Recursive Common Table Expressions (CTEs): The core of the solution leverages SQLite’s WITH RECURSIVE functionality. A CTE named CycleFinder performs a depth-first search through the family tree’s parent-child relationships.
Targeted Loop Detection: Instead of building a complete ancestor list for every person (which is inefficient for large databases), CycleFinder starts its search from every direct child-parent link in your database. It then attempts to trace ancestors from the parent’s side, looking for the original “child” that initiated that specific path.
Efficient Cycle Prevention: Early iterations struggled with performance due to string manipulation (INSTR function) within the recursive path tracking. The current design judiciously uses INSTR to prevent infinite recursion and detect general path revisiting, but the primary loop detection is based on the current_person_id eventually equalling the start_person_id (the child who began the trace). This balance significantly improved performance.
Canonical Loop Reporting: A RankedLoops CTE was introduced to address the challenge of reporting a single, meaningful instance for each unique loop. This CTE uses a sophisticated PARTITION BY clause that extracts all unique PersonIDs involved in a detected loop, sorts them, and concatenates them into a consistent “canonical loop identifier.” ROW_NUMBER() then selects the shortest or lowest-FamilyID loop from that canonical set, ensuring clean, non-redundant output.
User-Centric Output: Recognizing that RootsMagic users don’t see FamilyIDs, the final SELECT statement includes intelligent joins to the NameTable to convert FamilyIDs into human-readable “FatherName-ID=MotherName-ID” format, directly assisting users in locating and correcting errors within the RootsMagic application.
What Performance to Expect
The script is optimized for performance within the constraints of SQLite’s recursive CTE capabilities:
Small to Medium Databases: For databases up to tens of thousands of records, you can expect the script to execute very quickly, often in a matter of milliseconds to a few seconds.
Large Databases: For very large databases (e.g., hundreds of thousands of Child and Family records), the execution time will naturally increase. Recent tests on a database with 274,000 ChildTable records and 159,000 FamilyTable records completed in approximately 3 minutes 45 seconds on a 7-year-old Intel i5 processor. While this isn’t instantaneous, it is a very reasonable time for performing a comprehensive graph cycle detection on such a scale.
Factors Affecting Performance: Your computer’s processing speed (CPU, RAM, SSD vs. HDD) and the depth/complexity of your family tree (very long, unbroken lineages will require deeper recursion) will influence actual execution times.
In summary, the RM-LineageLoopDetector.sql script provides an efficient and user-friendly way to maintain the integrity of your RootsMagic family history data by accurately pinpointing and describing otherwise hidden lineage loops.
If you’ve read this far and want more detail on the development process, you should view the dialog I had with Gemini at https://g.co/gemini/share/2cdd5db67e6f.
I just finished a session with the free Google Gemini Flash 2.5 model to develop a quite complex query to identify couples in a RootsMagic database who are cousins of each other (see the discussion that led to it in the Forum at https://sqlitetoolsforrootsmagic.com/forum/topic/cousin-marriages/). That was preceded a few months back by a session with DeepSeek trying to develop a query that could act as an alternative to RM’s Set Relationships tool – it was not as successful but it might be more so now as its model evolves and grows. Anyway, that caused me to ask Gemini some questions about how to effectively use it to develop SQLite3 queries for RootsMagic databases. That “conversation” can be read in full at https://g.co/gemini/share/b9ef037e35c6 but I asked it to generate a summary for this post, pasted below.
Unlocking Your RootsMagic 10 Data: A Deep Dive into SQLite Queries
RootsMagic 10, like its recent predecessors, stores all your precious genealogical data in a robust SQLite database file (typically with a .rmtree extension). This self-contained, file-based relational database is embedded directly within the RootsMagic software, making it incredibly efficient for personal use.
While RootsMagic’s interface is fantastic for managing your family tree, sometimes you need to dig deeper – to run custom reports, analyze specific data patterns, or extract information in ways the software doesn’t natively offer. This is where direct SQLite querying comes in.
Key takeaways for RootsMagic users:
SQLite is Your Data’s Foundation: Your entire family tree, including persons, events, sources, citations, and media, resides within a structured SQLite database.
Access with Caution (and Backups!): You can explore your .rmtree file using third-party SQLite tools (like DB Browser for SQLite or SQLiteSpy). Always create a full backup of your database before attempting any direct access or modification!
Understanding the Schema is Key: To write effective queries, you need to know the specific table names (e.g., PersonTable, EventTable, SourceTable) and column names (e.g., FirstName, LastName, Date1, Title) within the RootsMagic schema. These are the “building blocks” of your queries.
How AI Can Help (with your input): AI models like Gemini can assist in generating complex SQLite queries. However, because they don’t have real-time access to your specific database’s schema, you’ll need to provide the relevant table and column names to ensure the queries are accurate.
Leverage Context in Conversations: If you’re working with an AI, you can generally continue to refine and develop multiple queries within the same chat session, as the AI will retain context of the schema details you’ve already provided. For new chat sessions, a quick reminder of the core table/column names will be helpful.
By understanding the SQLite foundation of RootsMagic and learning how to craft (or have an AI craft!) custom queries, you gain unparalleled power to analyze and utilize your genealogical data in new and exciting ways. Just remember the golden rule: Always back up your database before you begin!
That summary of the responses to my prompts up to that point of the session really missed a lot of what Gemini said so it’s worth delving into the conversation for more insight into points 4 & 5 and how an AI might become repetitive or forget or veer off due to an error in input or interpretation, as happened in my session with DeepSeek and even to a degree with Gemini that I was able to catch and correct.
I went on in the conversation with Gemini to discover that content lifted from the RM10 Data Dictionary in CSV format and pasted into the Chat could provide it with important parts of the database schema that it readily understood. Until now, I have been typing in the bare minimum description to provide the context with which the AI engine is to work. If a comprehensive description of the schema can be easily provided to the AI engine, that will make development of custom queries much easier. At the moment, the prompt capacity is not large enough to accept the entire sheet named “RM10 Data Def Project” as CSV text.
The raison d’etre of this website is to “Exploit your RootsMagic family tree database with SQLite Tools”. AI assistance in creating new and more powerful “SQLite Tools” looks to be within reach at no or low $cost for those with a good understanding of the RootsMagic database design and SQL.
Stemming from recent discussion in the RootsMagic Community about the desire for a system to track Feature Requests for the RootsMagic application, I was curious to see what might be readily available and came across a free plugin for WordPress: Simple Feature Requests Free – User Feedback Board By Patrick Garman. I’m not offering to host one for RM but I thought it might be useful to add it to this site to handle the occasional request for a SQLite-based tool for interaction with a RM database. You’re welcome to float a trial balloon to see how the plugin works and then delete your request if it’s nothing more than that. You can access the page via the top menu bar or directly at: Tool Requests.
I first reported on the #sqlean extensions for SQLite3 in my 2022 post In Praise of SQLite. What I did not pick up then that I have just now discovered is that sqlean supports the creation of user-defined or custom functions using SQLite syntax. Maybe it did not at that time or my fluency in the language of code development is just too poor to have recognised it. Regardless, I have now been enthusiastically exploring that capability, hitting lots of bumps but thrilled that, at last, I’ve found a way to take complex SQL and package it into a function that greatly simplifies and eases the development of scripts that interact with the RootsMagic database structure. And there is an acceptable penalty in performance that only becomes noticeable on large datasets or slow systems.
Moreover, a custom function can be easily created in #SQLiteSpy by copying a block of SQLite code from a working script into Notepad++ for minor changes and, thence, into the SQLiteSpy editor. To illustrate, I will focus on the conversion of the script in the post Date Decoder to the function rmDateDecode().
Performance
Custom functions may seem a simple matter for those with skills in a language that can interact with SQLite. For those of us closer to the luddite end of the spectrum, they seem out of reach. Some years ago when I saw that SQLite Studio supported custom SQLite functions, I dove in only to be greatly disappointed by its performance; that was a dead end. So I was delighted that there was no obvious penalty in moving a complex string parsing and conditional string building code from a script into a sqlean custom function, as reported in the table below.
rmDateDecode() tested on the same database having 8368 rows in the EventTable, 3940 of which had a text or valid date:
Regular SQL Script in SQLiteSpy 3.47.2
SQL function in SQLite Studio 3.4.13
sqlean SQL function in SQLiteSpy 3.47.2
~40ms
~44000ms
~60ms
Installing the extension
This message in the SQLiteSpy extensions dialog gave me pause (and still makes me a little unsure):
While I have experienced many bumps building the rmDateDecode() function, I have tested many of the functions included in sqlean and they all work. And, once working, my custom function has been reliable.
Download Windows 64-bit package and extract either define.dll (and other extensions, if desired) or the bundle of extensions included in sqlean.dll to the same folder as your executable for SQLiteSpy.exe Win64-bit edition.
The SQLiteSpy extensions dialog is accessed via the menu Options > Options > Extensions.
Type in the name of the extension file and, if not in the same folder, the relative or full path. Mine is in a sub-folder named ‘sqlean’. The extension will load the next time SQLiteSpy opens or connects to a database. It manifests itself as an empty table named ‘sqlean_define’ when there is no connected database.
With the extension successfully loaded, you’re ready to begin using functions built into sqlean. Try some examples from the Main Set. For the rest of this post, our attention will be on the define set.
Building a custom function per the instructions
I was puzzled at the outset that the examples for scalar functions did not seem relevant to what I wanted for decoding values from the Date column of RM’s EventTable. However, with a test RM database connected, I blundered ahead at making a simple function that would extract the first yyyymmdd string from [Date].
Executing that statement added the following record to the sqlean_define table:
name
type
body
rmDateExtract
scalar
SUBSTR(:rmDate,4 ,8)
…and did whatever is necessary in memory to make the function accessible to the SQLite engine.
‘:rmDate’ is what I chose as the name of the one variable to be passed to the function. Then the SQLite statement:
SELECT rmDateExtract([Date]) FROM EventTable;
…sends the value of the Date field from each row in the table to the function which returns the substring.
rmDateExtract(Date)
19200101
19180307
19920215
That’s certainly more readable than what is stored:
Date
rmDateExtract(Date)
D.+19200101..+00000000..
19200101
…but we want to do better. And here’s where the fun and frustration began.
Note that the define() syntax requires the SQL code to be a string within single quotes. However, the DateDecoder.sql script has string values to compare, to be concatenated, or empty strings to be issued. I ran into this issue using a Visual Studio C# years ago to build my old #rmtrix utility. Conversion of working, regular code of this sort into a string that would be correctly presented to the SQLite engine was a trial and error headache. A regular line like this:
I got it almost right using Notepad++ the first time but “almost” is a fail. Ultimately, after many fails, I narrowed it down to the empty string '' (2 single quotes). While '''-''' is needed to pass '-' to SQLite, '''''' does not pass on ''; the sequence '''' does! (those are all single quotes)
An easier, more reliable way to build a custom function
Here was the Eureka! Moment. What ended up in the sqlite_define.[body] cell was the original regular code. Moreover, that is a permanent table unless explicitly DROPped from the database. And whatever sqlean put into memory for a custom function is gone once SQLiteSpy is closed, maybe even when the database is disconnected. That implies that sqlean reads the table on opening or when a custom function is called and does its magic in memory. So what if I inserted an empty record into the table and edited it with SQLiteSpy directly to add a function? I copied the block of regular SQL into the [body] cell and filled the other two cells appropriately. Closed and reopened SQLiteSpy on the database and tried the function. Voila!
This is so much easier and is what one can do in the SQLiteStudio interface; it’s a pity that it is such a slug. Here’s a shot of the sqlite_define table contents with three user-defined functions:
A Caution
One thing I am experiencing which remains concerning is that on closing a connection or the app, I frequently, if not always, get the following error message since diving deep into custom functions with sqlean:
I also get a “database is locked” message at times when adding or editing a function in the sqlean_table. The two may be related but I do not know the cause. Hopefully, this is not a sign of possible corruption per the warning from the SQLiteSpy Extensions dialog window.
And there are sqlean instructions about memory:
define_free() Frees up occupied resources (compiled statements cache). Should always be called before disconnecting. E.g. select define_free();
I don’t know whether closing SQliteSpy releases the cache. If not, we’ll have to see if there is an erosion of available memory over time.
Please join me in welcoming Kevin McLarnon ( @kmclarnon ) in the role of Editor on this site and, especially, for volunteering to lead a renewed initiative to improve the documentation we have on the design of the RootsMagic v9 #database. He is counting on users better-versed than himself in sqlite3 and #RM9 (#RM10) to collaborate, contribute to and comment on the #datadefinitions but brings to the process experience with Google Workspace teams, websites and pedagogy.
The locus of activity is the page RM10 Data Dictionary which links to the collaborative spreadsheet on which all are invited to comment. Some of you will be approached for special contributions and you can also contact him directly. You will hear more from Kevin about the project in blog posts and/or Forum messages.
Richard Otter is a skilled, professional developer who is also a RootsMagic user and has been building a library of scripts that are worthwhile checking out for possible solutions for your own needs. He publishes them on GitGub, list of them screenshotted below 2023-05-19. Check for updates and fuller descriptions. He has posted notices of significant ones in the Forum and, hopefully, will continue to do so.
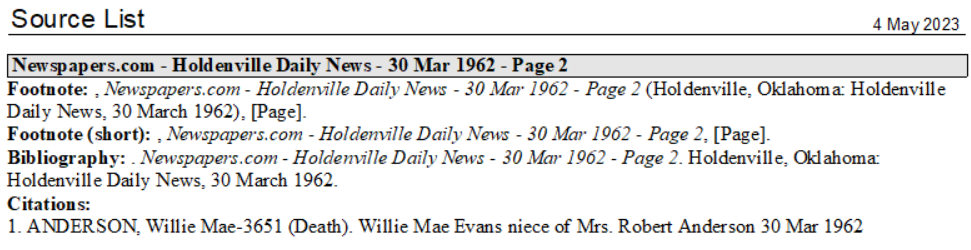
This project arose from a request Fix & Merge Hundreds of Newspapers.com Sources in the Forum. The poster is a heavy consumer of the Newspapers.com sources through RM’s TreeShare with Ancestry.com and had issues with:
A long Source List in the application and repetitiously long report Bibliographies due to a different Master Source for each page of a newspaper.
Repetitious listing of “Newspapers.com” in Source Names and in the Title in Bibliographies and in Footnotes. Her approach was to manually delete it in every Master Source but still had hundreds to do.
Leading punctuation in the Footnotes and Bibliographies because the Author value is empty in sources from this Ancestry collection.
“N.p.” and “n.d.” notations in Footnotes and Bibliographies when a value for Publisher, Publish Place or Publish Date is empty.
Solution
Because the sources were imported via TreeShare, they are Ancestry Record type, i.e., they are created using the built-in Ancestry Record Source Template. Built-in Source Templates are uneditable through the RM user interface but are defined in the same table that holds user-defined templates. Thus, the built-in templates can be modified by using SQLite to edit entries in the SourceTemplateTable. We can address Issues #3 and #4 by modifying the Footnote and Bibliography sentence templates in the Ancestry Record template. That will be of benefit also to citations having empty values from some other Ancestry Collections (see Ancestry TreeShare – Impact).
Issues #1 and #2 are more challenging because the values of the source and citation variables that appear in the Footnote and Bibliography sentences are stored in a XML data structure. To solve #1, we want to “lump” all citations of a given newspaper Title under one Master Source. That requires that the data that differentiates the Master Sources for a common newspaper must be deleted or transferred from the Master Source to the Citation Details. For example, the Page # must be extracted from the Source Name in the SourceTable and moved to the Detail ([Page] variable in XML) for each Citation of that Source in the CitationTable. There are more steps than that alone for each of that one newspaper’s multiple Master Sources and Citations.
Once all the data manipulations are complete, there will be multiple identical Master Sources for a given newspaper Title. RM’s AutoMerge Sources function can finish the job.
Before/After Screenshots
The database undergoing modification was from RM7, hence the screenshots are of RM7. However, the solution also works with RM8 and RM9.
Before
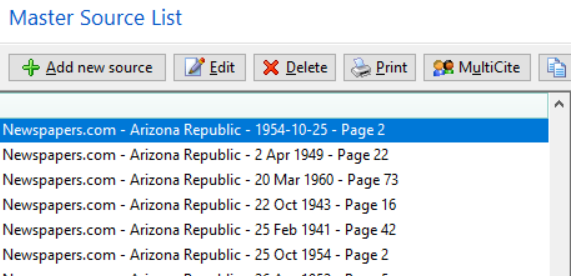
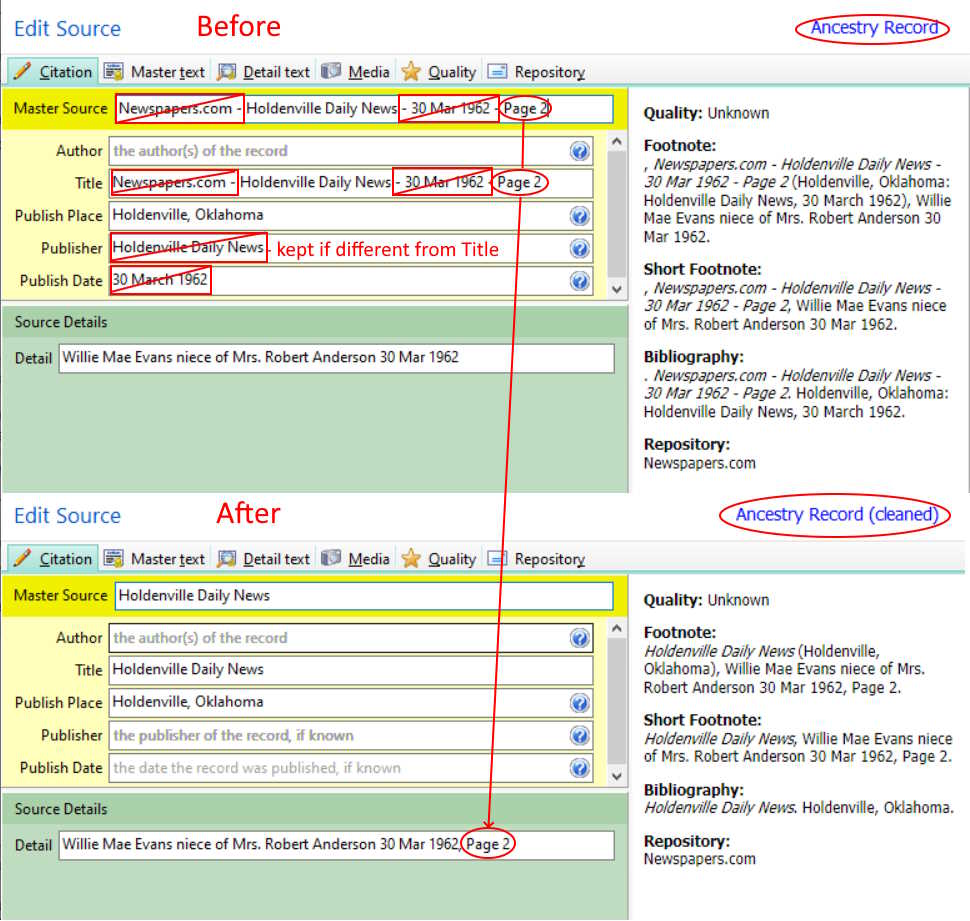
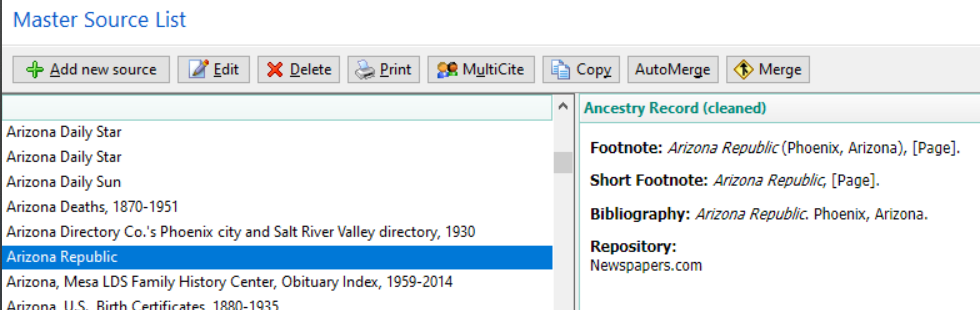
Example of one source in the original database. Note that the Source Name and the Title variable (italics) are identical and contain the unwanted “Newspapers.com”, the title of the newspaper, the publish date and the page number. The [Page] variable at the Citation level contains description of the item of interest and the publish date (repeated from the [Title] variable). All three sentences have unwanted leading punctuation and white space.A Master Source for each page cited from a given newspaper. This example of ‘extreme splitting’ of sources is perfectly acceptable for some users while, for others, the long Source List and report Bibliographies are objectionable and ‘lumping’ to one Master Source per newspaper is preferred.
Transition
These Before/After shots of the Edit Source window show the operations needed to prepare Sources and Citations for lumping Sources by Newspaper Title and the resulting sentence previews from an improved Ancestry Record source template.
After
Now just one Arizona Republic in the Source List instead of many individual Page #’s. In some cases such as the Arizona Daily Star at the top of the list, RM’s Source AutoMerge leaves two Master Sources that look identical and it is necessary to Manual Merge the two to end with just one. Despite fields looking identical in the Source Editor, AutoMerge compares the full XML strings of each source and there’s no match if the order of otherwise identical fields is different.
On returning to RM, run Rebuild Indexes in Database Tools.
In RM, open the Source List and run AutoMerge.
If you have two or so remaining sources for the same newspaper using the Ancestry Record template and you wish to have only one, use RM’s Manual Merge for Sources.
Repeat after you have added more Newspapers.com sources via TreeShare.
Notes
Should you have reason to revert the Ancestry Record source template to the format supplied by the application, load and execute in your SQLite manager SourceTemplate-AncestryRecord-Reset.sql, edited to find a RM database file of the same major version number to fetch the built-in format.
Should you upgrade or drag’n’drop to another database, the “Ancestry Record – cleaned” template will revert to the built-in format. Run step #4 on the target database to restore it.
The user reported that TreeShare does not report any change as a consequence of this procedure; it would seem to rely solely on the link to the Ancestry Record stored in the RM7 LinkAncestryTable (AncestryTable in RM8, RM9).
The procedures should work also on RM8 and RM9.
The main script is not what I would call ‘elegant’. It grew like Topsy as I explored the database and evolved the process through a sequence of building blocks. Someone cleverer than I with SQLite might well produce a better, faster version.
Conversion from #RM9 to #RM8 is pretty trivial with little loss except for RM9’s new features. From RM8 to #RM7 is much more complex given the significant structural changes between the two. To convert from RM9 to RM7 is simply a two-stage process with a RM8 compatible file as an intermediary. It’s possible to combine the two into one procedure but that’s for another time.
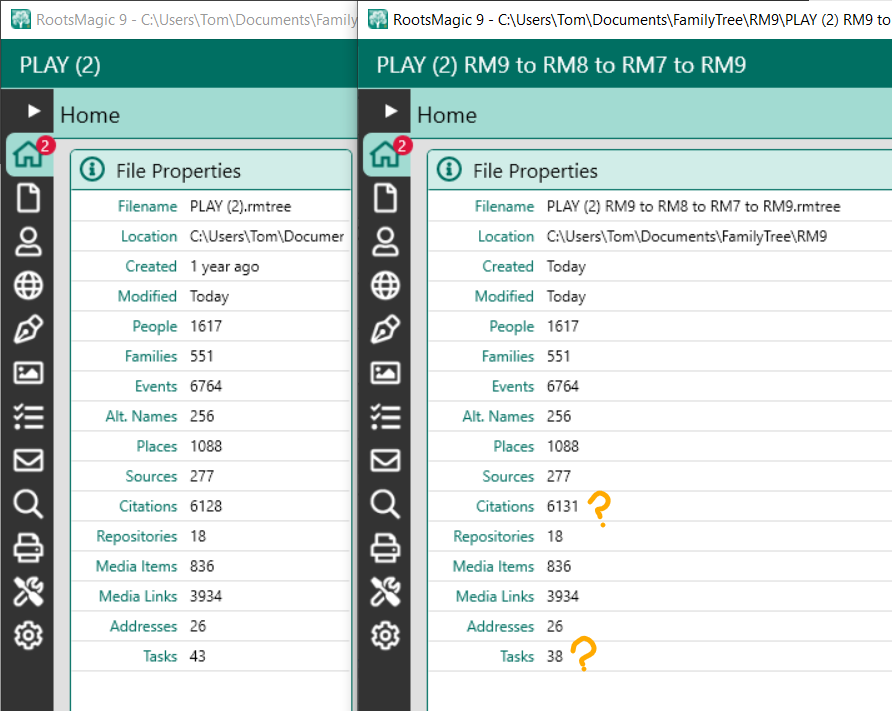
Losses
Comparison of database properties between the original RM9 database and after having been converted down to RM7 via RM8 and then upconverted back to RM9. Demonstrates that the core data has been preserved with the only variance in the number of Citations (0.05% increase) and the number of Tasks (12% decrease).
That there should be a variance in Tasks is unsurprising because of the structural changes between RM7 and RM9; Task Folders from RM9 could be non-existent in RM7.
The tiny variance in Citations is perhaps more surprising as it might be expected to go in the opposite direction, e.g., citations for Associations in the original RM9 database would be absent in RM7 and unrecoverable in the re-upgrade to RM9. In this case, however, it is because a few of the original RM9 Citations were reused and there were 6131 Citation Links which were transformed to 6131 individual Citations in the downgrade from RM8 to RM7.
The loss of Associations in the downgrade has no effect on the Events count as they are records in a different table, only reported in RM9’s Enhanced Properties List which also reveals the loss of Task folders.
Original RM9 database on the left; to the right is the traveller from RM9 down to RM7 and back.
Of course, the database properties lists do not tell the whole story. It would also be unsurprising to find that Notes, especially formatting, may not be preserved in a downgrade or upgrade due to the major reiterations of the Note Editor code. Certainly, new features in RM8 or RM9 will not be supported in a lower version and those that are database dependent, including Associations, Color Code Sets and Labels, and Saved Search Criteria cannot survive a round trip from a higher version to lower and back.
Stage 1: From RM9 to RM8
The only barrier to RM8 opening a RM9 .rmtree file is the version number of the database. For RM8, it cannot deal with a version higher than 8000; RM9’s is 9000 while RM7’s is 6000 (as it is for RM6). This statement opens the door to RM8:
UPDATE ConfigTable
SET DataRec=
CAST(
REPLACE(DataRec,'<Root><Version>9000</Version>',
'<Root><Version>8000</Version>')
AS BLOB
)
WHERE RecID=1
;
The next step is only needed to prevent RM8 from offering the Association fact type (which it cannot support) as a conventional individual type which one could use to add such events, leading to confusion should the database be reopened in RM9.
DELETE FROM FactTypeTable WHERE FactTypeID=902; -- Association Fact Type
--DELETE FROM EventTable WHERE EventType=902; -- Association individual event, if any
The second statement is only needed should such Association individual events have been created before upgrading back to RM9.
A possible enhancement to this down-conversion from RM9 to RM8 might be to convert Associations in RM9 to either Shared Events or simple individual type events with the name of the other person in the event description.
Stage 2: From RM8 to RM7
The heavy work in developing a procedure for this down-conversion was covered in Convert RM8 Database to RM7.
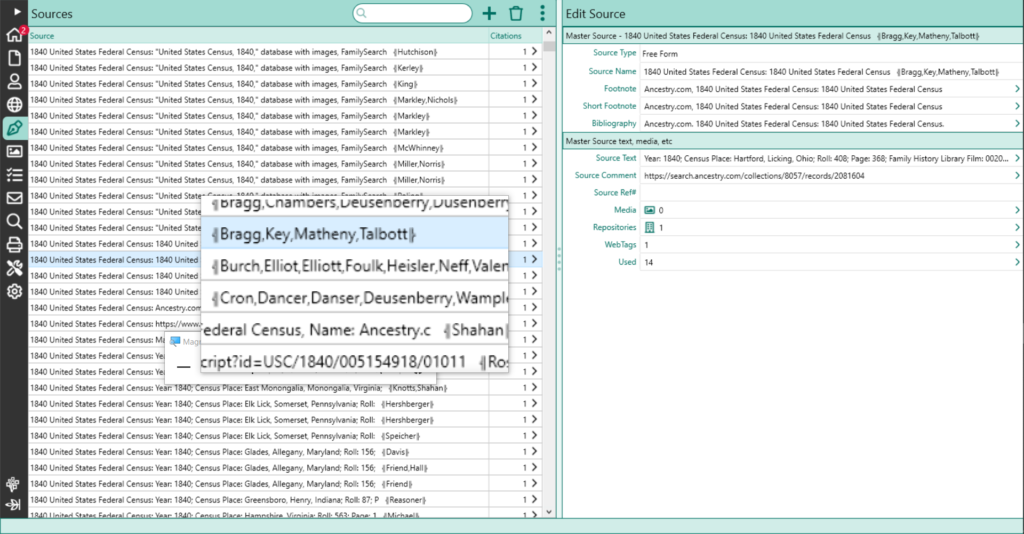
Sources view in RM9 after running the script to append Surnames of people using each Source.
In response to a request in the Forum, Adding Surname to Truncated Source Names in RM9, posted here is a script that may be of use to others. The user’s objective is to facilitate distinguishing which Master Sources (among many similar source names derived from imports from FamilySearch, Ancestry, et al) are relevant to families or persons of interest without clicking down through Citations, Citation Uses and dead ends from which he needs to back out to go onto the next. With 32k Sources, 32k Citations (he’s a ‘source-splitter’) and 113k ‘uses’ among 7k people and 3k families, one can appreciate the scope of his challenge.
Description
This batch script appends to the Source Name the unique surnames of all persons in the database who have a citation or ‘use’ of a Master Source in their profile. The list of surnames is enclosed in drawing symbols: ╣surnamelist╠ acting as bookends. The resulting extended name is gracefully truncated at 256 characters if caused by the operation, the maximum RM9 supports in a drag’n’drop transfer; the value is easily changed in four places in the same statement.
The script execution creates a series of temporary Views (in-memory queries) to build the final View “TruncNewName” from which the SourceTable is updated with the ╣surnamelist╠ appended. These Views are lost when the SQLite manager closes the database.
At the start of the script after REINDEXing against the fake RMNOCASE collation, the SourceTable is updated with Names stripped of previous ╣surnamelist╠. Therefore, the script can be rerun again after changes have been made in the database.
Because the database has been REINDEXed against the fake RMNOCASE, the RM Rebuild Indexes tool must be run on returning to work on the database with the RootsMagic app.
Execution time for the script on the sample database with 32k sources is 20-25 seconds on a 5-yr old i5, middling laptop with HDD so it is not prohibitively long to use repeatedly. I do not know how the time would scale with larger databases.
Requires
Requires a SQLite manager that has a “fake RMNOCASE collation” and supports REGEXP_REPLACE(). Script was developed and tested with SQLiteSpy 1.9.16 64-bit and the fake RMNOCASE extension from RMNOCASE – faking it in SQLiteSpy. Backup before using!
For source ‘lumpers’, the string of surnames might well be too long for the Source Name. Even for ‘splitters’, some source such as a census page for a residential school, hospital, prison could have a long list of surnames. The current Sources view in RM9 is amenable to showing only 100-150 characters depending on screen size and the position of the divider while a drag’n’drop truncates at 256. That may call for two things:
A similar procedure to append surnames to the Citation Name instead of the Surname which still risks field overflow and truncation for heavily ‘reused’ Citations, e.g., the above example and those sometimes resulting from the “Merge all duplicate citations” tool.
An enhancement to RM to provide a popout of the full content of the Source and Citation Names when hovered over or selected.
Working on this project has got me thinking about a means to differentiate what RM thinks are duplicate citations when they differ in Media or Web tags. Stay tuned…
And please comment here or in the Forum on whether this script does anything positive or negative for you!